



This is a guest blog by Daniel Wester, Chief Engineer in the Infrastructure & Operations group at Turner Broadcasting. I asked Daniel to share how they have scaled Bamboo as we are exploring similar at Twitter. Daniel will also be sharing the whole story at Atlassian Summit this October.
All opinions stated are mine and does not necessarily reflect those of Turner or any of its affiliates or partners.
At Turner Broadcasting System we build all of our code through the usage of Continuous Integration servers. We automate the deployment of the code to our servers using the artifacts from these builds. This means that our build servers are a crucial part in delivering new functionality (or applying fixes). One of the Continuous Integration servers that we use is Bamboo from Atlassian.
We require our Bamboo installs to be recoverable within minutes, even in the event of a hardware outage. The idea is for us to be able to flip the current primary server to be a standby server and promote a standby server to be the primary server in the event of a failure on the current primary server.
HA Bamboo Setup
First off, we’ll take a look at approaches to architecting Bamboo.
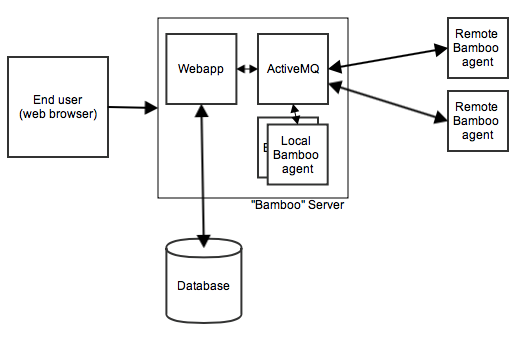
A normal Bamboo instance with a remote agent looks something like:
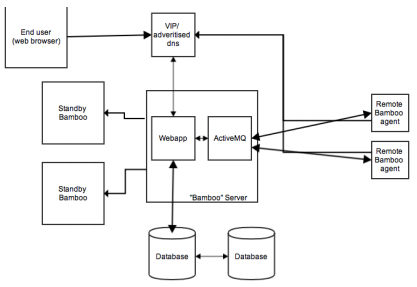
Our Bamboo HA setup at Turner looks like.
nginx handles requests
Starting at the front-end, we have nginx web server in front of the Bamboo web application. This allows us to cache the pages for anonymous users in the event Bamboo does go down.
Before we get to nginx though, we have a Virtual IP Address for Bamboo. We point the public DNS entry to this VIP to allow us to move the Bamboo web application to any server without having change the DNS entry. You can accomplish nearly the same thing using a CNAME, just make sure the TTL is low.
Bamboo on standby
For the major instances of Bamboo we have standby servers. These are servers that have all of the required components and configuration in order to run Bamboo at a moments notice.
Bamboo can utilize a wide range of database backends. We selected MySQL and set up a master/master configuration that we utilize in an active/passive manner. Data is replicated between at least 2 MySQL database servers and the Bamboo web application reads/writes from one of them. We selected this approach as Bamboo uses the database heavily and by pinning it to a single database we can simplify the setup. More on this later.
Remote agents
We attempt to avoid running local build agents. In fact when we do – we treat them as remote build agents and install the build dependencies (Maven, Ant, Phing, Ruby gems etc) using our Configuration Management system. This allows us to shift build functionality easily between servers and avoid snowflake build agents. Build agents are installed using the Configuration Management system.
Taking this approach allows us to easily recreate Bamboo web application servers, and remote agents, in the case of failure. The build environment is known to be the same (if their target usage is supposed to be the same).
If you have multiple remote agents on your Bamboo server – look into using a Configuration Management system to install everything on your servers since it will make everything identical while giving you flexibility to have variations, including the declaration of the properties in Bamboo. See Configuring remote agent capabilities for instructions on automatically configuring build agents.
When we install the agent – we specify the http://public-dns/agentServer/ to be the public dns entry. This means that if we shut down the Bamboo web app for a couple of minutes (upgrades, server maintenance etc) – when it comes back up – the agents will just reconnect by hitting the http url. The url returns back the ActiveMQ cluster host and connects to it.
We use a monitoring framework to verify that the agent is running on the remote agent server and if it’s not it starts the Bamboo remote agent. All of this means that if we shut down the Bamboo web application the agents automatically reconnect when it comes back online.
Bamboo home directory
The Bamboo home directory contains a lot of temporary data (jms-store, local git cache directories, etc). It also contains the configuration of your Bamboo instance (bamboo.cfg.xml which has the MySQL database connection, the ActiveMQ connection string and your license). We rsync the Bamboo home directory on a regular basis to each of the standby servers.
However, this causes a problem as you need to have Bamboo to ignore two settings in the bamboo.cfg.xml – the database host and the jms connection string. While you can’t pass in the database host on the connection (if you can – please let me know) we run a local port proxy (there are several ways of doing it: iptables, haproxy and so on) that forwards connections on a port on localhost to the database host. That way we can easily swivel the database connection.
However the switching between the database isn’t completely manual – we use our Configuration Management system for that. We also don’t necessarily require downtime (depending on if the databases are in sync).
The jms connection is a bit more fun. We simply pass that in on the command line when we start Bamboo up.
-Dbamboo.jms.broker.client.uri=failover:\(tcp://10.0.10.12:54663?wireFormat.maxInactivityDuration=300000\)?maxReconnectAttempts=10\&initialReconnectDelay=15000
This makes Bamboo ignore the setting in bamboo.cfg.xml and we end up with a “clean” bamboo home directory. As with everything else – we use our Configuration Management system to actually write the proper values in place.
So there you go – that’s our Bamboo instance. All powered through Configuration Management systems – if we need to move any component – we simply flip the flags in the Configuration Management system and things just happen. The CM’s config incidentally is built and tested using Bamboo and the CM’s Bamboo instance is maintained through the CM.
Thanks for sharing how to configure Bamboo for an HA environment Daniel. Folks, don’t forget Daniel is sharing more on the Turner approach to Continuous Integration at Atlassian Summit this coming October 1 – 3 in San Francisco, be sure to check it out!
